
Help & Knowledge Base
Customizing Result File Names
Special keywords can be used as placeholders in the output file names, to be replaced with dynamic values during the execution.
A trivial example is prefixing each document with the page number, when splitting.
[CURRENTPAGE]
A reference to the current page number in the input document.
Example: [CURRENTPAGE###] will generate filesnames like 001.pdf, 002.pdf.
Example: [CURRENTPAGE##] generates 01.pdf, 02.pdf, etc.
[TIMESTAMP]
Ensures unique output filenames, being replaced with current date & time.
[FILENUMBER]
Ensures unique output filenames, replaced with a file number according to the output order.
Example: [FILENUMBER###] generates 001, 002
Example: [FILENUMBER13] starts with the counter at 13, generating 13, 14,
etc.
[BASENAME]
Does not ensure unique output filenames, and it must be used together with other placeholders ensuring unique names. It is replaced with original name of the input document, without the extension.
Example: [CURRENTPAGE]_[BASENAME] would generate 1_input-file.pdf, 3_input-file.pdf,
etc.
[BOOKMARK_NAME]
This pattern is replaced by current bookmark's name. Only applicable in the "Split by bookmarks" tool.
[BOOKMARK_NAME_STRICT]
Same behavior as [BOOKMARK_NAME] with the difference that non-alphanumberic characters are
removed.
Example: [CURRENTPAGE]-[BOOKMARK_NAME] would generate 1-Introduction.pdf, 4-Chapter
1.pdf, etc.
[TEXT]
This pattern is applicable only in the "Split by text" tool. It is replaced with the text found in the page area selected.
Example: [CURRENTPAGE]-[TEXT] would generate 1-Invoice 3456789.pdf, 4-Invoice
234567.pdf, etc.
[TEXT1], [TEXT2], etc.
This pattern is applicable only in the "Rename" tool. It is replaced with the text found in the selected area.
Example: [TEXT2]-[TEXT1] would generate John Doe-Invoice 3456789.pdf, Jane Doe-Invoice
234567.pdf, etc.
Sejda Desktop Enterprise Install
To deploy Sejda Desktop in an enterprise environment using a pre-configured volume license key use this command:
msiexec /i sejda-desktop_x.y.z_x64.msi LICENSE_KEY="1234-ABCD-1234-ABCD"
Any options provided will be configured machine-wide and will apply for all users on the system.
| LICENSE_KEY | License key | LICENSE_KEY="1234-ABCD-1234-ABCD" |
| LOCALE | UI language | en, es, de, fr,it or pt |
| UPDATE_CHECK | Disables checking for new versions | UPDATE_CHECK="false" |
| DISABLED_FEATURES | List of features to be disabled | DISABLED_FEATURES="edit.whiteout" |
| EULA_ACCEPTED | Accept EULA and no longer prompt on first use | EULA_ACCEPTED="true" |
| AUTO_REPORT_ERRORS | Configure automated error reporting and no longer prompt on first use | AUTO_REPORT_ERRORS="false" |
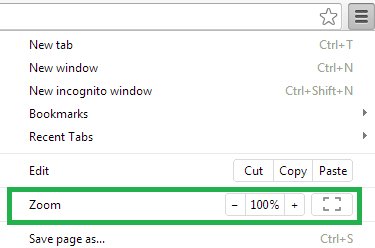
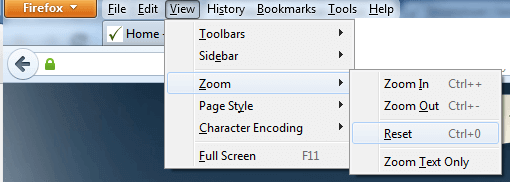
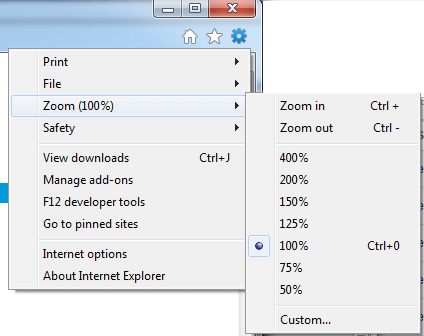
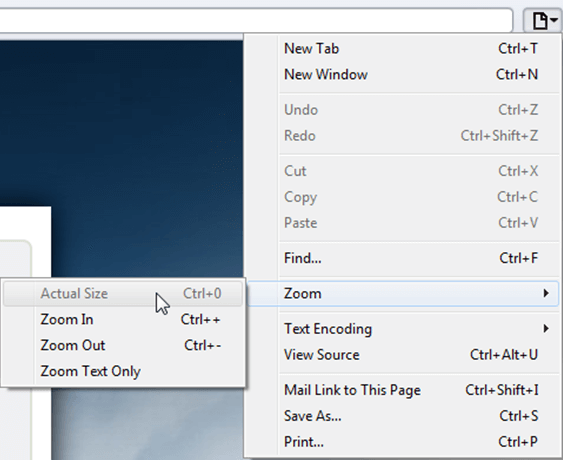
Resetting Browser Zoom
Choosing a zoom level of anything other than 100% (the default) can cause problems in pages where we render PDF pages.
If you are warned about it, reset the browser zoom to 100%.
The quickest way to return your browser to this zoom setting is to use the keyboard shortcut Ctrl + 0 on Windows or Cmd + 0 on Mac.
Additional browser-specific instructions for changing the zoom level are detailed below.
Chrome
Firefox
Internet Explorer
Safari
Sejda Desktop - Loading local fonts failed
Sejda Desktop fails to load the fonts installed on your system?
Windows 7: Please install "Platform update for Windows 7 SP1": https://support.microsoft.com/en-us/kb/2670838.
Linux: Please install libfontconfig-dev: sudo apt-get install libfontconfig-dev
Sejda Desktop - Add your fonts
Sejda Desktop can use your custom fonts when editing PDF documents.
1) Install the font on your system. See help for Windows or Mac.
2) Open Sejda Desktop, then open a PDF document with the Editor.
3) Type text on the page. From the context menu select "Fonts > More fonts".
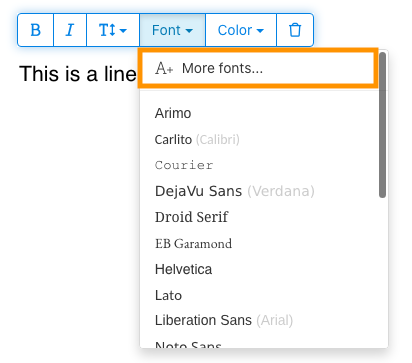
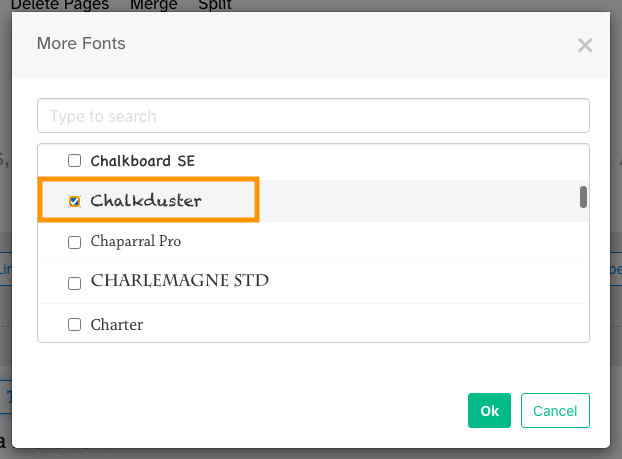
4) Select the font you would like to use and click "OK".
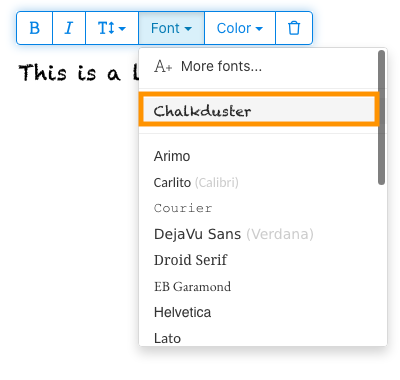
5) Click on the newly added font to use it for your text.
How long does it take for a refund to be processed?
It can take anywhere from 5-10 business days for a refund to show up on your bank account.
In some cases, the refund might be processed as a reversal, meaning the original payment will disappear from the account statement entirely and the balance will reflect as though the charge never occurred.
If you do not see the refund after 10 business days and you are still seeing the original charge on your bank statement, please reach out to support for more information.
How can you delete your FastSpring data?
If you've placed an order through FastSpring, our online authorized reseller & merchant of record, you can send your data erasure request to privacy@fastspring.com.
Malwarebytes interfering with Sejda Desktop?
Do you have Malwarebytes installed?
Please try temporarily turning Malwarebytes off and see if that solves the problem: Instructions here
You can report this problem with Malwarebytes: Report false positive
Could not convert: Page uses CAPTCHAs
The website you are trying to convert uses CAPTCHAs to block automated robots (such as our converter) from visiting their website.
There is no work around this.
See if the browser extension helps with your use-case:
HTML to PDF browser-extension
Install Linux OCR engine
Sejda Desktop does not ship with an embedded OCR engine on Linux, it uses the one available on the system.
To install an OCR engine, please run the following command:
sudo apt-get install -y tesseract-ocr tesseract-ocr-all
Once the command completes, return to Sejda Desktop and run your OCR task again.
Install Linux OCR language data
The OCR engine is installed successfully, but it is missing language data.
To install language data, please run the following command:
sudo apt-get install -y tesseract-ocr-all
About 667M of data will be downloaded and installed.
Once the command completes, return to Sejda Desktop and run your OCR task again.
I'm being asked to enter the owner password
Why am I being asked for a password?
Some PDF documents come with security settings that restrict certain actions, such as printing, copying text, editing, or adding annotations. These restrictions are implemented by the document's creator to control how the content is used and shared.
When we detect that a PDF has these restrictions, we prompt you for the owner password. Entering this password unlocks the document and grants full access to all features and permissions. This step ensures that only authorized individuals can modify or remove the restrictions set by the original author.
What is an owner password?
An owner password is set by the creator of the PDF to prevent unauthorized changes to the document. It differs from a user password, which restricts opening the document altogether. If you have the owner password, it means you have full permission to the document.
What If I don't have the owner password?
If you don't have the owner password, you will continue to have limited access based on the restrictions set in the PDF.
To gain full access, obtain an unlocked version of the document.
How can I avoid having to repeatedly type in the owner password each time?
You can use a PDF unlocker tool to remove the permission restrictions from your document. You only do this once. Then you won't be prompted for the owner password for the document anymore.
Open the PDF document in Google Chrome, press Ctrl+P to print, choose "Destination" to be "Save as PDF" in the top right side, then click "Save".
Will purchasing a paid plan solve the problem?
No, you will still be asked for the owner password even if you have a paid plan with us.
Can you tell me the owner password?
No, we don't know the owner password for your documents. The owner password was chosen by the person that created your document, and is different from your login password.
I can't edit or convert a scanned document
Why scanned documents cannot be edited or converted?
When you scan a physical document to create a PDF, the scanner captures an image of each page. This process converts the text, graphics, and layout into a single image file embedded within the PDF. Unlike standard PDFs, where text is stored as individual characters and lines that can be selected, copied, and edited, scanned PDFs treat each page as one large picture.
Because the text in a scanned PDF is part of an image, PDF editors cannot recognize or modify it directly. The software sees only a collection of pixels, not distinguishable letters or words. This makes it impossible to edit text paragraphs or make changes as you would in a regular, text-based PDF document.
How to determine a document is a scan?
One way to determine if a PDF is a scanned image is to open it with a PDF viewer and by trying to select the text with your mouse. In an editable PDF, you can highlight text by clicking and dragging your cursor over it. If you're unable to select any text and the entire page behaves like a single image, it's likely a scanned document.
Note: Some scanned documents are processed with Optical Character Recognition (OCR) to become "searchable" scans, where text can be selected and searched. However, these documents are still scans and cannot be edited or converted like standard PDFs.
I'm sure my document is not a scan
Some documents resemble scans because their content is embedded as images on each page. This can happen with documents created from screenshots or when text has been converted to outlines instead of being embedded as editable text.
While these aren't technically scans, they function similarly. Unfortunately, we also don't support editing or converting these types of documents.
Will purchasing a paid plan solve the problem?
No, upgrading to a paid plan will not enable you to edit or convert scanned documents. Editing or converting scans is not supported, regardless of your subscription level.
I am sure I was able to edit this document previously
We have never supported editing or converting scanned documents. If you were able to edit the document before, it's likely that it was exported to PDF differently than the current document.
Sejda Desktop fails due to permissions
There are 2 common causes for this error: insufficient permissions or antivirus interference.
Insufficient permissions: You may need to run Sejda Desktop with Administrator priviledges. Right-click the app, then choose "More" > "Run as admininstrator".
Antivirus or Security software: Try temporarily disabling your antivirus to verify if that helps solve the problem.
Slow upload/download speeds in India
Significant submarine cable outages impact multiple network carriers on the Indian subcontinent, causing slow upload/download speeds. See upstream incident details
Please use Sejda Desktop as a workaround, which processes files locally, no upload/download being required.
We apologize for the ongoing inconvenience created by this extraordinary situation.